Log File Analysis For SEO
Log file analysis is a lost art. But it can save your SEO butt. This post is half-story, half-tutorial about how web server log files helped solve a problem, how we analyzed them, and what we found. Read on, and you’ll learn to use grep plus Screaming Frog to saw through logs and do some serious, old school organic search magic (Saw. Logs. Get it?!!! I’m allowed two dad jokes per day. That’s one).
If you don’t know what a log file is or why they matter, read What Is A Log File? first.
The Problem
We worked with a client who rebuilt their site. Organic traffic plunged and didn’t recover.
The site was gigantic: Millions of pages. We figured Google Search Console would explode with dire warnings. Nope. GSC reported that everything was fine. Bing Webmaster Tools said the same. A site crawl might help but would take a long time.
Phooey.
We needed to see how Googlebot, BingBot, and others were hitting our client’s site. Time for some log file analysis.
This tutorial requires command-line-fu. On Linux or OS X, open Terminal. On a PC, use a utility like cmder.net.
Tools We Used
My favorite log analysis tool is Screaming Frog Log File Analyser. It’s inexpensive, easy to learn, and has more than enough oomph for complex tasks.
But our client’s log file snapshot was over 20 gigabytes of data. Screaming Frog didn’t like that at all:
screaming-frog-log-choke-compressed
Screaming Frog says « WTF? »
Understandable. We needed to reduce the file size, first. Time for some grep.
Get A Grep
OK, that’s dad joke number two. I’ll stop.
The full, 20-gig log file included browser and bot traffic. All we needed was the bots. How do you filter a mongobulous log file?
- Open it in Excel (hahahahahahaahahahah)
- Import it into a database (maybe, but egads)
- Open it in a text editor (and watch your laptop melt to slag)
- Use a zippy, command line filtering program. That’s grep
“grep” stands for “global regular expression print.” Grep’s parents really didn’t like it. So we all use the acronym, instead. Grep lets you sift through large text files, searching for lines that contain specific strings. Here’s the important part: It does all that without opening the file. Your computer can process a lot more data if it doesn’t have to show it to you. So grep is super-speedy.
Here’s the syntax for a typical grep command:
grep [options][thing to find] [files to search for the thing]
Here’s an example: It searches every file that ends in “*.log” in the current folder, looking for lines that include “Googlebot,” then writes those lines to a file called botsonly.txt:
grep -h -i ‘Googlebot’ *.log >> botsonly.txt
The -h means “Don’t record the name of the file where you found this text.” We want a standard log file. Adding the filename at the start of every line would mess that up.
The -i means “ignore case.”
Googlebot is the string to find.
*.log says “search every file in this folder that ends with .log”
The >> botsonly.txt isn’t a grep command. It’s a little Linux trick. >> writes the output of a command to a file instead of the screen, in this case to botsonly.txt.
For this client, we wanted to grab multiple bots: Google, Bing, Baidu, DuckDuckBot, and Yandex. So we added -e. That lets us search for multiple strings:
grep -h -i -e 'Googlebot' -e 'Bingbot' -e 'Baiduspider' -e 'DuckDuckBot' -e 'YandexBot' *.log >> botsonly.txt
Every good LINUX nerd out there just choked and spat Mountain Dew on their keyboards. You can replace this hackery with some terribly elegant regular expression that accomplishes the same thing with fewer characters. I am not elegant.
Breaking down the full command:
h: Leaves out filenames
i: Case insensitive (I’m too lazy to figure out the case for each bot)
e: Filter for multiple factors, one factor after each instance of -e
>>: Write the results to a file
Bots crawl non-page resources, too, like javascript. I didn’t need those, so I filtered them out:
grep -h -v *.js botsonly.txt >> botsnojs.txt
-v inverts the match, finding all lines that do not include the search string. So, the grep command above searched botsonly.txt and wrote all lines that did not include .js to a new, even smaller file, called botsnojs.txt.
Result: A Smaller Log File
I started with a 20-gigabyte log file that contained a bazillion lines.
After a few minutes, I had a one-gigabyte log file with under a million lines. Log file analysis step one: Complete.
Analyze in Screaming Frog
Time for Screaming Frog Log File Analyser. Note that this is not their SEO Spider. It’s a different tool.
I opened Screaming Frog, then drag-and-dropped the log file. Poof.
If your log file uses relative addresses—if it doesn’t have your domain name for each request—then Screaming Frog prompts you to enter your site URL.
What We Found
Google was going bonkers. Why? Every page on the client’s site had a link to an inquiry form.
A teeny link. A link with ‘x’ as the anchor text, actually, because it was a leftover from the old code. The link pointed at:
inquiry_form?subject_id=[id]
If you’re an SEO, you just cringed. It’s duplicate content hell: Hundreds of thousands of pages, all pointing at the same inquiry form, all at unique URLs. And Google saw them all:
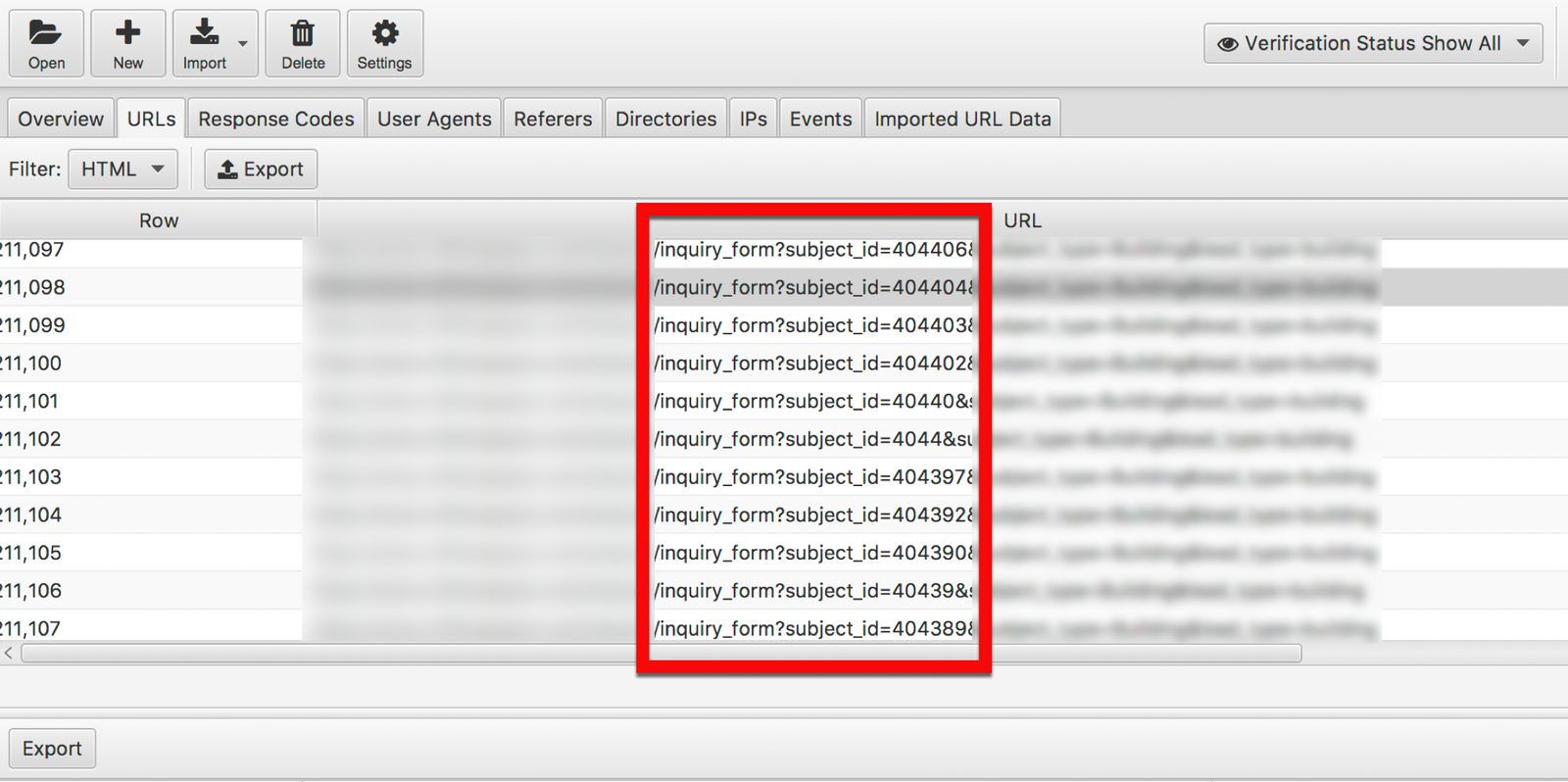
log-files-inquiry-form-compressed
Inquiry Forms Run Amok
60% of Googlebot events hit inquiry_form?subject_id= pages. The client’s site was burning crawl budget.
The Fix(es): Why Log Files Matter
First, we wanted to delete the links. That couldn’t happen. Then, we wanted to change all inquiry links to use fragments:
inquiry_form#subject_id=[id]
Google ignores everything after the ‘#.’ Problem solved!
Nope. The development team was slammed. So we tried a few less-than-ideal quick fixes:
- robots.txt
- meta robots
We tried rel canonicalNo, we didn’t, because rel canonical was going to work about as well as trying to pee through a Cheerio in a hurricane (any parents out there know whereof I speak).
Each time, we waited a few days, got a new log file snippet, filtered it, and analyzed it.
We expected Googlebot to follow the various robots directives. It didn’t. Google kept cheerfully crawling every inquiry_form URL, expending crawl budget, and ignoring 50% of our client’s site.
Thanks to the logs, though, we were able to quickly analyze bot behavior and know whether a fix was working. We didn’t have to wait weeks for improvements (or not) in organic traffic or indexation data in Google Search Console.
A Happy Ending
The logs showed that quick fixes weren’t fixing anything. If we were going to resolve this problem, we had to switch to URL fragments. Our analysis made a stronger case. The client raised the priority of this recommendation. The development team got the resources they needed and changed to fragments.
That was in January:
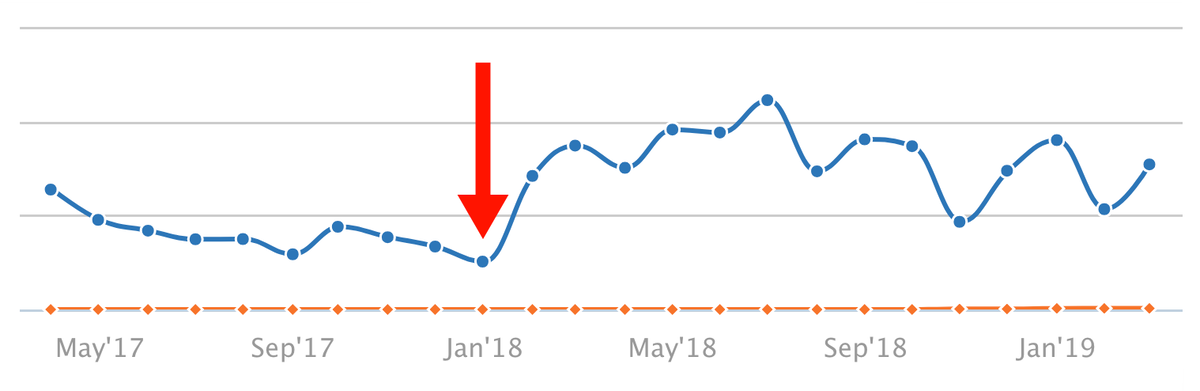
fragments-implemented-compressed
Immediate Lift From URL Fragments
These results are bragworthy. But the real story is the log files. They let us do faster, more accurate analysis, diagnose the problem, and then test solutions far faster than otherwise possible.
If you think your site has a crawl issue, look at the logs. Waste no time. You can thank me later.
I nerd out about this all the time. If you have a question, leave it below in the comments, or hit me up at @portentint.
Or, if you want to make me feel important, reach out on LinkedIn.
The post Log File Analysis For SEO appeared first on Portent.